Claude Code ソースコード解説シリーズ 第13章: 業界の Agent 協調(選択)
業界の複数 Agent 設計を横断比較し、仕事の分割と収束の仕方を整理します。
『Claude Code ソースコード解析シリーズ』第13章|業界のエージェント協働(オプション)
前節では、Claude Code のソースコードの視点から、AgentTool、subagent、fork、Task、SendMessage、Coordinator、Team といったメカニズムを分解して見てきた。
この節では視点を変えて——Claude Code の外に目を向け、業界がどのようにマルチエージェント協働を設計しているかを見ていく。
このテーマは、ともするとプロダクト名の羅列になりがちだ。
- Gemini / ADK には
SequentialAgent、ParallelAgent、LoopAgentがある。 - Claude Code には subagents と agent teams がある。
- Codex には subagents、custom agents、sandbox、approvals がある。
- OpenAI Agents SDK には handoffs と
Agent.as_tool()がある。 - Deep Agents には supervisor、sync subagents、async subagents、memory、sandbox がある。
しかし、こうした名称だけを覚えても、読み終わったあともやもやが残る。
マルチエージェントにおいて本当に難しいのは、「複数のモデルインスタンスを起動できるかどうか」ではない。難しいのは次の問いだ。
タスクをどう分割するか?
誰が仕事を割り振るか?
子エージェントはどれだけのコンテキストを参照できるか?
子エージェントはファイルを変更できるか?
完了後、結果をどう親に戻すか?
行き詰まったときに停止できるか?
複数のエージェントが同じ箇所に書き込んで競合しないか?
高リスクな操作を誰が承認するか?そこで、この節ではベンダーごとに概念を丸暗記するのではなく、一連の問題チェーンに沿って進んでいく。
より具体的にするために、前節の例を引き継ごう。
ユーザーがログイン失敗のバグ修正を要求したとする。
このバグは、auth コード、cookie 設定、データベースのセッション、フロントエンドのログインページ、
テストモック、旧APIの互換性、セキュリティ境界にまたがる可能性がある。
1つのエージェントでも対応できるが、遅くて混乱するだろう。
複数のエージェントでも対応できるが、協働の設計がなければ、より速く混乱するだけだ。この節で問うべき核心はこれだ。
業界のマルチエージェントシステムは、どのようにして「複数の知的エージェント」を制御可能な工学的協働として設計し、互いに汚染し合うモデルの群れに終わらせないようにしているのか?
1. まず問題の連鎖を整理する
マルチエージェントが登場する理由は、通常「モデルが十分に賢くないから」ではない。エンジニアリング上のタスクには、本来的に四つの圧力がかかっている。
第一に、情報が多すぎる。
ログイン不具合を修正する際、メインエージェントは数十のファイルを読み、テストを実行し、ログを確認し、呼び出しチェーンを探索しなければならない可能性がある。中間過程をすべて一つのコンテキストに押し込むと、メインの流れが検索ノイズに埋もれてしまう。
第二に、タスクは並列化できる。
呼び出しチェーンの調査、テストの実行、フロントエンドの状態確認、セキュリティ境界の精査——これらは本来同時に進められる。一つのエージェントに逐次処理させるのが常に最適とは限らない。
第三に、役割が異なる。
探索者は読むことを中心に、変更は最小限にすべきだ。実装者は最小限の修正に集中する。レビュアーは実装者の前提を疑うべきだ。セキュリティレビュアーは悪用可能なリスクを優先的に探すべきだ。これらの役割を一つのプロンプトに押し込めば、しばしば互いに衝突する。
第四に、リスクは収束させなければならない。
サブエージェントが「自分はバックグラウンドワーカーだから」という理由で権限を迂回してはならない。互換ロジックの削除、データベーススキーマの変更、ネットワーク経由の依存関係取得、危険なコマンドの実行——こうした操作は、統一された承認と責任のチェーンに必ず戻さなければならない。
そこで、業界の設計はおおむね次のような連鎖に沿って進化してきた。
単一エージェントで単純タスクを完了できる
-> 複雑なタスクがメインコンテキストを汚染する
-> サブエージェントを導入しコンテキストを分離する
-> サブタスクを並列化できる
-> supervisor / worker による fan-out / fan-in(タスク分散と集約のパターン)を導入する
-> サブタスクの種類が異なる
-> 特化エージェントとツール権限の境界を導入する
-> 一部のタスクでは制御権を実際に引き渡す必要がある
-> handoff(制御権の移譲機構)を導入する
-> 一部のタスクはシステムやチームをまたぐ
-> A2A のようなプロトコル化された相互運用を導入する
-> 一部のタスクは長時間に及び、一気に完了できない
-> 耐久実行(durable execution)、メモリ、サンドボックス、タスクライフサイクルを導入するしたがって、マルチエージェントの本質は次のようなものではない。
more agents = more intelligenceむしろ、こうだ。
more agents = more coordination problems業界のあらゆる設計は、本質的に同じ問いに答えている。
並列処理能力を高めつつ、コンテキスト・状態・権限・責任の境界をいかに失わないか?
2. 第一のパターン:中央集権型オーケストレーション ―― まず「統括役」を置く
最も堅実なマルチエージェントのパターンは、中央集権型オーケストレーションです。
システム内にまず、全体を統括する役割を置きます。
ユーザーリクエスト
-> メイン Agent / Runner / Supervisor が目標を理解
-> いくつかのサブタスクに分解
-> 各サブ Agent に割り振り
-> サブ結果が戻るのを待つ
-> 統括役が総合・判断・後続の実行を行うこれは典型的な fan-out / fan-in(分散送出、集約回収)です。タスクが一つの中心点から放射状に広がり、完了後に再び中心点へ戻って統合されます。
シーケンス図で表すとこうなります。
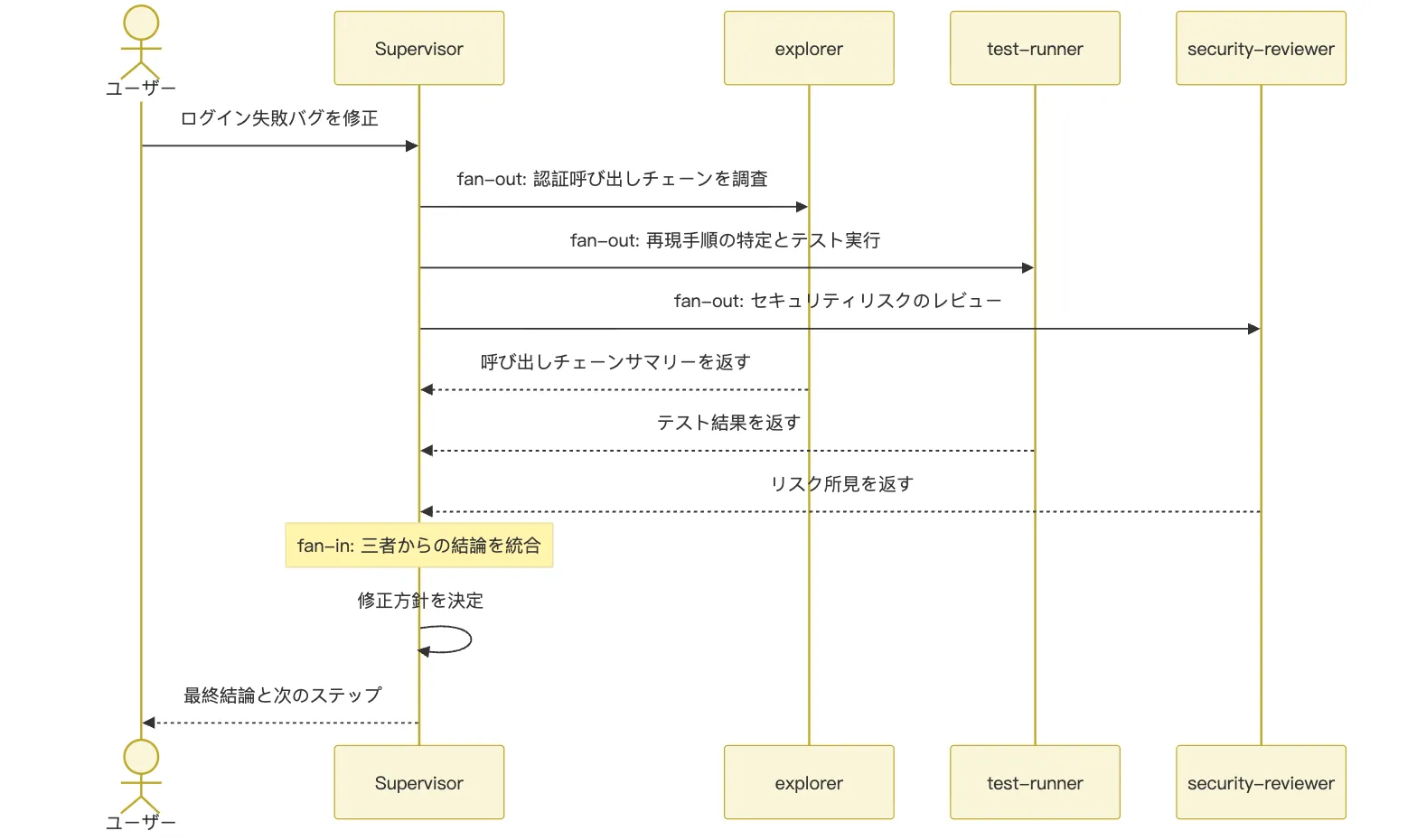
ログインのバグに当てはめてみましょう。
統括 Agent:
- code-mapper に認証の呼び出しチェーン調査を指示
- test-runner に再現手順の特定とテスト実行を指示
- security-reviewer にリスク評価を指示
- 最終的な修正方針とマージ判断は自身で保持このパターンの利点は明快さです。各サブ Agent は局所的な仕事をこなし、統括役が大局判断を担います。サブ Agent は全体を知る必要はなく、自分で最終方針を決めるべきでもありません。
OpenAI Agents SDK の Agent.as_tool() は、この考え方を端的に具現化したものです。orchestrator(オーケストレーター)が specialist agent をツールとして呼び出し、制御権は常に orchestrator の手にあります。Claude Code や Codex における多くの subagent のシナリオも同様の趣です――親 Agent が明示的に仕事を割り振り、子 Agent が結果を返し、親 Agent がそれを統合します。
これが解決するのは、次の根本的な問いです。
マルチエージェントシステムにおいては、「最終的に話をまとめる」役を誰かが担わなければならない。
さもなければ、各 Agent がそれぞれ自分の局所的な視点から結論だけを提示してしまいます。
テスト Agent:テストはレッドです。
セキュリティ Agent:ここにリスクがあります。
実装 Agent:修正しました。
フロントエンド Agent:画面表示は正常です。しかし、ユーザーが本当に必要としているのはこれです。
根本原因は何か?
どこを修正したのか?
なぜその修正方法が安全と言えるのか?
どのテストが、従来の振る舞いを壊していないことを証明しているのか?
他にどんなリスクがあるのか?これは必ずセントラルノードが最終統合を行う必要がある。
ただし、セントラルなオーケストレーションにも限界はある。すべてのコミュニケーションがマスターを経由すると、マスターがボトルネックになる。タスクが長く、サブタスクが多く、サブエージェント間で頻繁なやり取りが必要な場合、セントラルノードは判断する代わりに情報の転送に追われることになる。
そこで業界は第二のパターンへと進んだ。コラボレーションをオブジェクト化する、というアプローチだ。
(要するに、セントラルなオーケストレーションは「最も安全なデフォルト」である。どう設計すべきか迷ったときは、まず一人に全体責任を持たせれば、大きな混乱にはならない。)
3. 第二のパターン:タスクのオブジェクト化 — 自然言語だけで仕事を割り振らない
マルチエージェントで最も避けるべきなのは「口頭での仕事の割り振り」です。
メインエージェントがサブエージェントにこう言ったとします:
ログインの問題を見てきて。これだけでは曖昧すぎます。サブエージェントは次のことを知りません:
- 読み取り専用の分析か、コードを変更してもよいのか?
- 出力は証跡なのか、解決策なのか?
- 途中で行き詰まったらどうするのか?
- 完了条件は何か?
- 結果を他のエージェントに共有すべきか?
成熟したシステムでは、タスクをオブジェクトとして扱います。
タスクには最低限以下のフィールドが必要です:
id
description
owner / assignee
status
dependencies
allowed tools
artifacts
logs
result summary
cancel / resume capabilityGoogle の A2A プロトコルは Task を基本作業単位とし、タスクには完全なライフサイクルがあります。Claude Code teams は共有タスクテーブルとファイルロックを使用します。Codex はサブエージェントにスレッド上限、ネスト深さ、実行時間制限を設定します。Deep Agents の非同期サブエージェントはタスク ID を返し、スーパーバイザーはいつでも check、update、cancel、list できます。
これらの設計に共通するのは:
サブエージェントは「その場で呼び出したモデル」ではなく、ライフサイクルを持つ実行体である。
ログインバグの例に戻りましょう:
task: trace-auth-callers
owner: explorer
status: running
mode: read-only
output:
- 主要な呼び出しチェーン
- 疑わしい分岐
- 除外したパス
- 次のステップの提案メインコントローラーはサブエージェントの発言を逐一監視する必要はありません。適切なタイミングでタスクの状態と最終サマリーを読めば十分です。
タスクのオブジェクト化は、もう一つの隠れた問題も解決します:復旧です。
長時間のタスクが途中で中断された場合、システムは少なくとも次のことを把握している必要があります:
どのタスクが完了したか?
どのタスクが失敗したか?
どのタスクがまだ実行中か?
どの結果がすでに artifact として書き出されたか?
どの結論が中間的な推測に過ぎないか?タスクオブジェクトがないと、復旧はチャット履歴をさかのぼって推測するしかない。(午前3時の本番障害を経験した人ならわかるはずだ——こんなときに一番したくないのが「AIが何を言ったか最初から読み直す」ことだ。)
これこそが、本物のAgentランタイムが単なるプロンプトラッパーではなく、「タスクシステム+ツールシステム+状態システム」の組み合わせへと必然的に収斂していく理由である。
4. 第三のモード:コンテキスト分離、サブエージェントは要約を返し、ノイズを返さない
マルチエージェントが最初に解決しようとしたのは並列性ではなく、コンテキスト汚染だった。
Claude Code のサブエージェント、Codex のエクスプローラ、Deep Agents のサブエージェントはいずれも、次の一点を強調している。
サブエージェントは深く探索し、試行錯誤できる
メインエージェントは圧縮された結果のみを受け取るこれは極めて重要だ。
ログインバグの修正時、探索エージェントは多くの高ノイズな動作を行う。
session を検索
cookie を検索
login を検索
古いテストを読む
無関係なモジュールをいくつか除外する
失敗ログの一部を確認する
一度誤判定する
修正するこれらのプロセスは探索エージェント自身には有用だが、すべてをメインエージェントに渡すべきではない。
メインエージェントが本当に必要とするのは、次のような情報だ。
どのパスを調査したか
どれが除外できるか
本当に怪しいのはどの3箇所か
証拠はそれぞれどのファイルにあるか
次の検証ステップとして何を提案するかサブエージェントの出力は要約であるべきで、書き起こしであってはならない。
これは実際のチームコラボレーションに喩えられる。午後いっぱいの検索履歴をすべて同僚に読み上げてもらったりはしないだろう。期待するのは「調べ終わった。問題はおそらく session refresh にあり、証拠が2つある。cookie 方面は除外できる」という報告だ。
これこそがコンテキスト分離の価値である。
しかし、分離には代償もある。サブエージェントが十分なコンテキストを参照できない場合、探索の重複、目標の誤解、さらにはメインの流れと矛盾する結論を導く可能性がある。
業界では通常、次の2つの戦略を使い分けている。
| 戦略 | 適した場面 | リスク |
|---|---|---|
| clean context(クリーンコンテキスト) | サブタスクが独立しており、探索ノイズが大きい | 背景の再理解が必要 |
| fork / inherited context(継承コンテキスト) | 親コンテキストの価値が高く、複数方向を並行検証したい | コストが高く、親コンテキストの誤った仮定を継承する可能性もある |
Claude Code の fork は後者に属する。親セッションの現在の状態から分岐し、複数のサブエージェントが同じプレフィックスを共有した上で、それぞれ異なる方向を探索する。
コンテキスト設計は、分離すればするほど良いというものではない。鍵となる問いはこれだ。
サブタスクにとって、親コンテキストの継承とクリーンな状態の維持、どちらがより重要か?
5. 第四のパターン:ロール特化 — Agent ごとに異なるツール境界を持つ
マルチ Agent とは、同じ Agent を 3 つ複製することではない。
3 つの Agent がいずれも読み取り・書き込み・削除・コマンド実行・ネットワークアクセス・設定変更を行えるなら、それは単に不安定な全権限のコピーが 3 つあるだけだ。
業界でより一般的なのは、ロールに応じて能力を制限するアプローチである。
Codex の公式ドキュメントには、default、worker、explorer といったロールが組み込まれている。explorer は明示的に read-heavy なコードベース探索に特化しており、カスタム agent では model、reasoning effort(推論の深さ)、sandbox(サンドボックス、隔離実行環境)、MCP server なども設定できる。Claude Code の subagent は Markdown frontmatter(フロントマター)で name、description、tools を定義し、subagent ごとに異なるコンテキストウィンドウとツールアクセス範囲を持たせられる。Deep Agents の subagent 設定にも、同様に name、description、system_prompt、tools、model、permissions といったフィールドがある。
これらの設計に通底する原則は極めてシンプルだ。
探索者:多読、少改、できれば読み取り専用。
実装者:変更可能だが、明確に定められた範囲内のみ。
レビュアー:diff とコンテキストのみ読み取り、リスクの発見を優先。
ドキュメント調査者:公式ドキュメントは参照できるが、プロダクトコードには触れない。
セキュリティレビュアー:より保守的な権限、より厳格な出力。ログインバグに当てはめると:
| Agent | タスク | ツール境界 |
|---|---|---|
| explorer | auth の呼び出しチェーンを特定 | ファイル読み取りと検索のみ |
| worker | session refresh ロジックを修正 | ワークスペース書き込み権限、範囲外への越境不可 |
| test-runner | ログイン関連テストの実行 | テストコマンドは実行可能、実装の変更は不可 |
| security-reviewer | cookie、token、権限リスクの精査 | 読み取り専用、findings を出力 |
| docs-researcher | フレームワーク API の挙動を検証 | ドキュメント MCP にアクセス可能、コード変更不可 |
役割の専門化が解決するのは「誰が何をするか」であり、ツール境界が解決するのは「誰が何をしてはいけないか」である。
後者のほうが前者より重要だ。
モデルはミスをする。本当に信頼できるシステムとは、プロンプトで「勝手に変更しないでください」と言うだけでは不十分で、ツール層、サンドボックス層、承認層で境界をしっかりと固める必要がある。
6. 第五のパターン:ハンドオフ、いつ本当にバトンを渡すべきか
中央オーケストレーションでは、サブエージェントはツールに近い存在です。局所的なタスクを完了し、結果をメインコントローラーに返します。メインコントローラーが常にセッションの制御権を握っています。
しかし、これが適さないシナリオもあります。
ユーザーの質問が「ログインのバグ修正」から次のように変わったとします。
ついでに新しいSSO(Single Sign-On、シングルサインオン、一組の認証情報で複数システムにアクセスできる仕組み)の
導入案も設計してほしい。これはもはや元のワーカーの局所的なタスクではなく、別の専門領域です。こうした場合、より合理的なのはハンドオフです。
現在のエージェントがタスクタイプの変化を認識
-> SSOスペシャリストにセッションを引き継ぐ
-> スペシャリストが後続の複数ターンの対話を担当
-> 最終結果を出すか、再度引き継ぐまで継続OpenAI Agents SDKはこの区別を明確に説明しています。
| パターン | 制御権 | 適したシナリオ |
|---|---|---|
| agent as tool | メインコントローラーが制御権を保持 | 局所的な専門タスク、レビュー、クエリ、補助的な分析 |
| handoff | 制御権を下流のエージェントに切り替え | ユーザーの意図が別の専門領域に切り替わり、下流での継続的な対話が必要な場合 |
この二つのパターンは混同しやすいものです。一言で区別するなら:
agent as tool:専門家にサブ質問に答えてもらう。
handoff:この問題はこれ以降、専門家に任せる。エンジニアリングエージェントにおいて、ハンドオフを乱用してはいけません。
小さな分岐ごとにハンドオフすると、ユーザーはシステムが次々と担当者を変えているように感じ、メインの流れも途切れてしまいます。より堅実なデフォルトの選択肢は通常、agent-as-tool / サブエージェントです。つまり、局所的な処理は専門家に任せ、メインコントローラーが総合するという形です。
タスクの「主語」が本当に変わったときにだけ、ハンドオフは価値を持ちます。
7. 第六のパターン:プロトコル化された相互運用──Agent は単一プロダクト内だけで協調すべきではない
ここまで紹介したパターンの多くは、同一ランタイム内部で完結するものだった。Claude Code における subagent の起動、Codex における worker / explorer の起動、Deep Agents における supervisor から subagent への指示、OpenAI Runner における handoff といった具合だ。
しかし業界には、より大きな問いが残っている。
異なるフレームワーク、異なるベンダー、異なるチームが作った Agent 同士を、どう協調させるのか?
ここに A2A(Agent-to-Agent)誕生の背景がある。
A2A は、リモートの Agent を発見可能・呼び出し可能・追跡可能なサービスとして扱うことを目指している。相手の内部実装を知る必要はなく、双方が共通のオブジェクトモデルに従えばよい。
Agent Card :私は誰か、何ができるか、認証方式は何か
Message :一回の通信内容
Task :状態を持つ一つの仕事
Artifact :タスクの成果物
Streaming / Push:タスクの進捗通知と長時間タスクの通知これは MCP と似ているが、関心領域が異なる。
MCP は「Agent がツールやリソースをどう呼び出すか」に近い。
A2A は「Agent が別の Agent をどう呼び出すか」に近い。ログインバグの例で言えば、社内に既存のセキュリティレビュー用 Agent サービスがあり、それが現在の Codex / Claude Code プロセス外で動いているとしよう。主制御側は A2A を通じてその能力を発見し、レビュータスクを送信し、その状態と Artifact をサブスクライブできる。
プロトコル化設計が解決するのは組織横断の協調である。
- 各チームが自身の specialist agent を独立に保守できる。
- 呼び出し側は相手の内部プロンプトやツールチェーンを知らなくてよい。
- 長時間タスクは Task ステートマシンで追跡できる。
- 結果は Artifact として標準化された形で返される。
- 認証と能力宣言は Agent Card に収められる。
しかし、これは新たな複雑さももたらす。
プロセスを跨ぎ、ネットワークを跨ぎ、組織を跨ぐなら、システムは以下の課題と向き合わなければならない。
認証
認可
タイムアウト
リトライ
バージョン互換性
タスクキャンセル
出力の信頼度
機密データの境界A2A は「Agent 同士が自由におしゃべりする」ためのプロトコルではない。リモート Agent をサービス化し、タスク化し、状態化するためのプロトコルなのだ。
これは Gemini / ADK 体系の中でも特に際立った特徴である。単にいくつかのワークフローエージェントを提供するだけでなく、エージェント間の相互運用性の問題をプロトコル層にまで押し上げている点だ。
8. 第七のモード:長時間実行 Harness──エージェントは記憶し、一時停止し、再開し、監査可能でなければならない
タスクが数分から数時間、場合によっては日をまたぐ実行時間になると、マルチエージェントには新たな課題が生じる。
たとえば:
ログイン不具合の修正
→ 認証ライブラリのアップグレードが必要と判明
→ 旧セッションのマイグレーションが必要
→ 完全なリグレッションテストの実施
→ 互換性戦略についてユーザーの承認待ち
→ マイグレーション文書の生成これは一度のモデル呼び出しで解決できるものではない。
長時間タスクには harness が必要になる:
短期状態:現在のスレッドが何を実行中か
長期記憶:セッションをまたいで再利用可能な事実や嗜好
タスク状態:どのタスクが完了・失敗・キャンセルされたか
artifact:中間成果物がどこに保存されているか
sandbox:実行環境をどのように隔離するか
approval:リスクの高いアクションをどのように一時停止し人間を待つか
tracing:問題発生時にどのステップで壊れたかを追跡する方法Deep Agents の設計はこの方向性をよく表している。同プロジェクトは自身をエージェント harness と位置づけており、LangGraph ランタイムを基盤に、planning、subagent、filesystem context、long-term memory、sandbox、human-in-the-loop(人間がループの中に留まり、重要な意思決定ポイントで承認を行う)を組み合わせている。その async subagent によって、supervisor はバックグラウンドタスクを起動し、task id を受け取ったあともユーザーとの対話を継続し、後から check、update、cancel できる。
Codex もこの方向に進んでいるが、表現はよりコーディングランタイム寄りだ:
- subagent には並列スレッド数の上限がある。
- ネストの深さはデフォルトで制限される。
- sandbox と approval policy が実行境界を制御する。
- app / CLI / cloud 間で一貫した実行モデルを共有する。
- 自動承認 review は本来承認が必要なアクションのみを評価対象とする。
こうした設計の背後にある中核的な判断は次のとおりだ:
エージェントはいったん長時間実行が可能になると、ガバナンス可能なワークフローとして振る舞わなければならない。一回限りのチャット応答としてではない。
tracing がなければ、失敗しても原因箇所が特定できない。
sandbox がなければ、能力が高いほど危険になる。
memory の境界がなければ、誤った情報が長期間保存されてしまう。
approval がなければ、子エージェントがリスクの高いアクションをバックグラウンドに隠蔽してしまう可能性がある。
タスクライフサイクルが存在しないため、中断からの再開は人間の記憶に頼るしかない。
長時間タスク向け Agent の鍵は、モデルの持久力を上げることではなく、システムがその「持久」プロセスを支えられるようにすることだ。
9. 複数システムを一枚の図にまとめる
ここで、業界のいくつかの路線を並べて見てみよう。
| システム / フレームワーク | 性格づけ | 協調の中核 | 強み | 主な限界 |
|---|---|---|---|---|
| Gemini / ADK / A2A | エンタープライズ向けオーケストレーション&相互運用プラットフォーム | workflow agents + A2A Task / Agent Card | プロトコル化、タスク状態管理、システム横断的な協調 | 内部のスケジューリング詳細は依然ブラックボックス、エンジニアリング負荷が高い |
| Claude Code | ターミナル上の協調ワークベンチ | subagents + context isolation + teams / mailbox | ローカル開発体験、コンテキスト分離、チーム協調の手応え | teams の復旧、コンフリクト収束、プロトコル化の度合いは弱め |
| Codex | 強い中央制御のコーディング実行カーネル | parent fan-out / fan-in + custom agents + sandbox / approvals | 承認、セキュリティ境界、宣言的な並行設定、コーディングワークフロー | 中央制御寄りで、自由な swarm ではない |
| OpenAI Agents SDK | プログラマブルな Agent オーケストレーション API | handoffs + agents as tools + Runner tracing | 制御権のセマンティクスが明快、プロダクション組み込みに適する | タスクオブジェクトや権限戦略は開発者が自前で設計する必要がある |
| Deep Agents | 長時間タスク向け Agent ハーネス | supervisor + sync / async subagents + memory / sandbox | 長時間タスク、永続化、プラガブルバックエンド | preview 機能と分散ガバナンスは自前での補完が必要 |
この表は優劣をつけるためのものではなく、各システムがどのレイヤーの問題を解こうとしているのかを整理するためのものだ。
- 大きなタスクを複数の読み取り専用探索に分解したいだけなら? Claude Code / Codex の subagent で十分だ。
- プロダクトのバックエンドで複数の専門家をオーケストレーションしたいなら? OpenAI Agents SDK の handoff と
Agent.as_tool()のほうが直接的だ。 - チームやシステムをまたいだ Agent サービスの相互運用をしたいなら? A2A のようなプロトコルに注目すべきだ。
- 数時間に及び、一時停止・再開が可能で、長期的な記憶を伴う複雑なタスクをこなしたいなら? Deep Agents のようなハーネスの発想が目標とする姿により近い。
10. マルチエージェント設計における業界の共通認識
これらのシステムを横断して見ると、いくつかの実用的な共通認識が浮かび上がってくる。
1. まずタスク境界を分割し、そこからエージェントを分割する
いきなり「エージェントは何個必要か」と問うのではない。まずこう問うべきだ:
どの作業が独立して完結できるか?
どの作業がコンテキストを共有する必要があるか?
どの作業が読み取り専用か?
どの作業が副作用を生むか?
どの結果をマスターが統合しなければならないか?タスク境界が明確になれば、エージェント数は自然と決まる。
2. 読み取りタスクは並列を優先し、書き込みタスクは集約する
並列に最適なもの:コード検索、ドキュメント参照、ログ確認、互いに影響しないテスト実行、候補案の分析、独立したレビュー。
自由な並列に最も適さないもの:複数エージェントによる同一ファイルの同時編集、同時スキーマ移行、共有メモリの同時更新、リリース戦略の同時決定。
一言で言えば:
読み取りは分散してよく、書き込みは集約せよ。3. サブエージェントは結論を返し、プロセスのノイズは返さない
サブエージェントの成果物は、以下の構造に固定するのが望ましい:
何をしたか
何を発見したか
証拠はどこにあるか
何を除外したか
推奨される次の一手は何か
不確かな点は何かすべてのツール呼び出し、検索結果、失敗経路をマスターコンテキストにそのまま流し込んではいけない。
4. 権限はモデルの自信ではなく、ロールに紐づける
モデルが「確信がある」と言っても、権限を委譲してよいことにはならない。
より信頼性の高いアプローチ:
explorer はデフォルトで読み取り専用
reviewer はデフォルトで読み取り専用
worker はワークスペースへの書き込みに限定
ネットワークはデフォルトで無効
危険なコマンドは承認必須
サンドボックス越境は承認必須これは Codex の sandbox / approval、Claude Code のサブエージェントツール、Deep Agents のパーミッション、Gemini のプラットフォームガバナンスが共通して指し示す方向性でもある。
5. 人間は下位のフォールバックではなく、高リスクな意思決定ノードである
マルチエージェントシステムは、ユーザーを「モデルが対応できないときだけ尋ねる相手」と見なすべきではない。
ユーザーはむしろ、リスク境界上の承認者である:
互換性の破壊を受け入れるか?
古いパスを削除するか?
ネットワーク経由で外部リソースにアクセスするか?
移行を実行するか?
長期記憶として保存するか?マルチエージェント化が進むほど、いつ人間を呼び戻すかを明確に定義しなければならない。
6. tracing は単なる付加機能ではない
単一Agentのエラーなら、チャット履歴をさかのぼれば済む。
マルチAgentのエラーでは、tracing がないと次のような状況に陥る:
どのAgentが見誤ったのか分からない
どのhandoffでコンテキストが欠落したのか分からない
どのツール呼び出しが状態を汚染したのか分からない
どのサブタスクが誤った内容をartifactに書き込んだのか分からない成熟したシステムは、tracing、使用量、タスクステータス、artifact、承認記録をすべて第一級オブジェクトとして扱う。
11. 導入可能な設計テンプレート
エンジニアリング向けのマルチエージェントシステムを自前で設計する場合、この最小テンプレートから始めるとよい。
Supervisor
- ユーザー目標の理解を担当
- タスク一覧の維持
- サブタスクの割り当て
- 結果の収集
- 最終的な意思決定
Task Ledger
- id
- status
- owner
- dependencies
- artifacts
- cancel / resume
Specialized Agents
- explorer:読み取り専用の探索
- worker:局所的な実装
- reviewer:独立したレビュー
- tester:検証と再現
- docs-researcher:外部ドキュメントの照合
Context Policy
- ノイズの多い探索にはクリーンなコンテキストを使用
- 並行する仮説検証にはフォークしたコンテキストを使用
- Supervisor への戻りはサマリのみ
Permission Policy
- デフォルトは読み取り専用
- 範囲を限定した実装にはワークスペースへの書き込みを許可
- ネットワーク / 外部書き込み / 破壊的コマンドは承認必須
Observability
- 全ツール呼び出しをトレース
- ハンドオフを記録
- タスクステータスを記録
- アーティファクトはチャット履歴とは別に保存ログインバグのフローに当てはめると次のようになる。
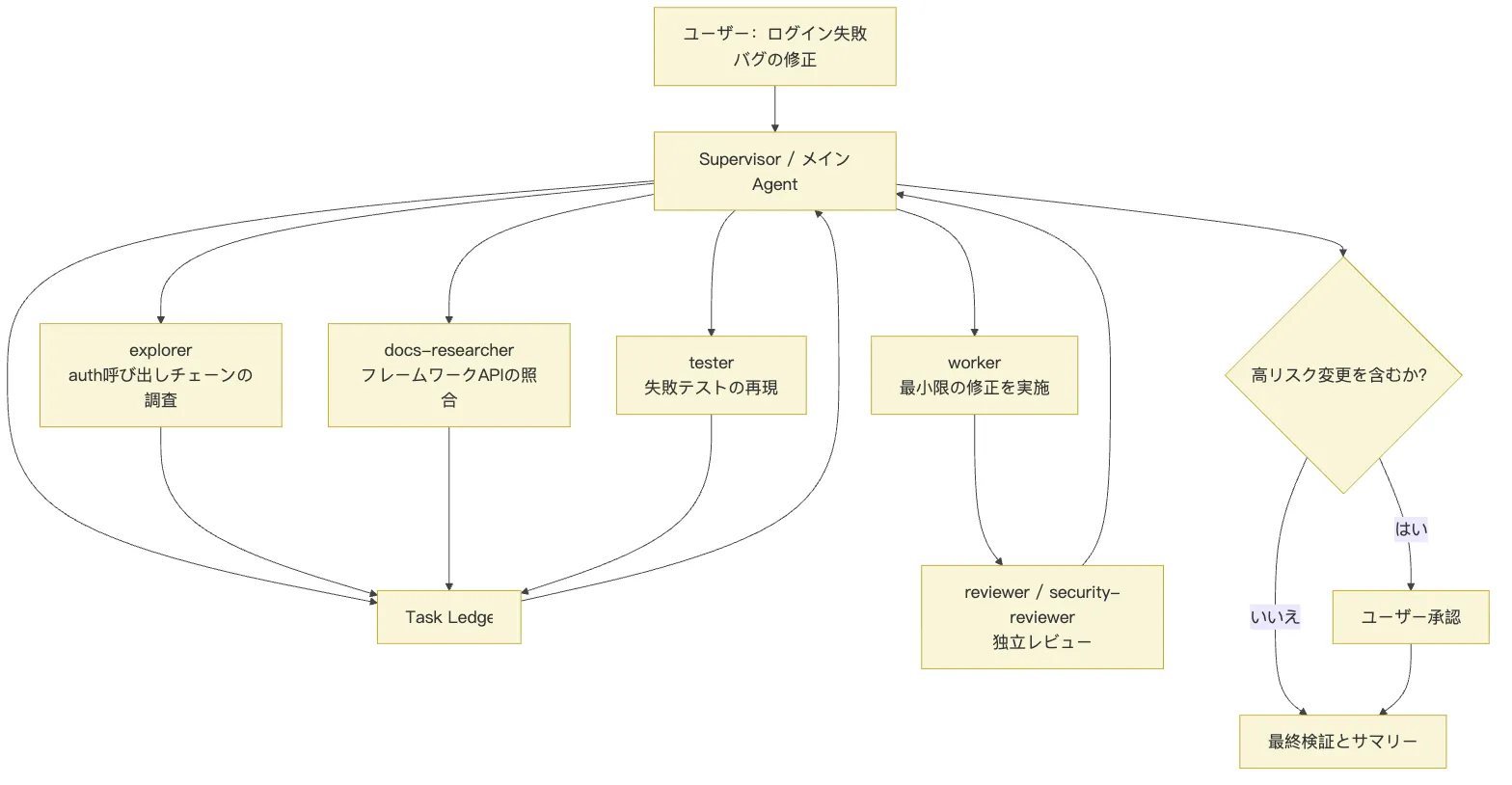
この図で重要なのはエージェントの数ではなく、境界である。
- 読み取りタスクは並行実行する。
- 書き込みタスクは収束させる。
- レビューは独立して行う。
- 高リスクな判断は人間に戻す。
- 最終判断は Supervisor が統合する。
12. Claude Code に戻る:なぜこれほど多くのオブジェクトが必要なのか?
業界の視点を得た上で、前節の Claude Code のソースコードを見返すと、理解が容易になる。
AgentTool は「モデルがモデルを呼ぶ」仕組みではない。制御されたディスパッチの入り口である。
subagent は「別のチャット窓」ではない。コンテキスト分離ユニットである。
fork は「セッションをコピーして遊ぶ」ものではない。親コンテキストを継承し、仮説を並行検証する戦略である。
Task システムは「バックグラウンドタスクリスト」ではない。マルチ実行体のライフサイクル管理である。
SendMessageTool は「Agent にチャットさせる」ものではない。プロトコル化された通信の入り口である。
Coordinator / Team は「マルチ Agent の見せびらかし」ではない。タスク組織化手法のアップグレードである。
AskUserQuestion / 権限エスカレーションは「ユーザーを中断させる」ものではない。高リスク判断を責任主体に戻す仕組みである。
Claude Code のマルチ Agent 機構は、業界の中で孤立した存在ではない。Gemini、Codex、OpenAI Agents SDK、Deep Agents と共に、同じ方向へ収束しつつある。
モデルの能力を、組織化可能・追跡可能・復旧可能・承認可能・分離可能なエンジニアリングシステムに包み込む。ただ、各社の重点は異なる。
Claude Code はローカルなエンジニアリングコラボレーション体験を重視し、Codex は中央実行カーネルとセキュリティ承認を重視し、Gemini はプロトコル化とプラットフォーム化を重視し、OpenAI Agents SDK はプログラマブルなオーケストレーションを重視し、Deep Agents は長時間タスクのハーネスを重視している。
13. 最後に一言で覚える
マルチエージェントは、システムをより「賢く」見せるためのものではない。
本当に解決しているのは、これだ:
タスクがあまりにも大きく、汚く、長く、危険なとき、
それを複数の隔離可能・並列可能・通信可能・停止可能・監査可能な実行単位に
どう分解するか。マルチエージェントの設計が妥当かどうかを判断するには、まずエージェントの数を見るのではなく、次の6つの問いに答えられているかを見るべきだ:
最終的な意思決定は誰が担うのか?
タスクの状態はどこにあるのか?
コンテキストはどのように隔離されるのか?
権限はどのように縮退させるのか?
結果はどのように伝達されるのか?
失敗はどのように回復するのか?この6つの問いに明確に答えられなければ、マルチエージェントは混乱を並列化するだけに終わる。
この6つの問いに明確に答えられてこそ、マルチエージェントは「複数のチャット欄」から「エンジニアリングのコラボレーションシステム」へと真に昇華する。